這篇主要記錄如何將HBase(0.20.3)當作Hadoop MapReduce程式的輸入來源,下述的程式碼很單純的從一個Table取出資料並直接輸出至HDFS上:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class TestTableInput
{
public static class Map extends TableMapper<Text, Text>
{
@Override
public void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException
{
String v = Bytes.toString(value.value());
context.write(new Text(Bytes.toString(value.getRow())), new Text(v));
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text>
{
@Override
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException
{
context.write(key, new Text(values.iterator().next()));
}
}
public static void main(String args[]) throws Exception
{
if(args.length != 2)
{
System.out.println("Usage: hadoop jar TestTableInput.jar <table> <output>");
System.exit(-1);
}
String tablename = args[0];
String output = args[1];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
fs.delete(new Path(output), true);
Job job = new Job(conf, "TestTableInput");
Scan scan = new Scan();
TableMapReduceUtil.initTableMapperJob(tablename, scan, Map.class, Text.class, Text.class, job);
job.setJarByClass(TestTableInput.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path(output));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}

這裡值得注意的有二個地方,一個是Map必須繼承HBase所提供的TableMapper(其實TableMapper也是繼承於Mapper),它用來指定KEYIN和VALUEIN兩個類別,它們分別為:ImmutableBytesWritable、Result,而這兩個類別分別對應的Table資料如下:
.ImmutableBytesWritable = Row Key
.Result = Row Key+Column+Timestamp+Value
另一個值得注意的是在main方式中用到的TableMapReduceUtil.initTableMapperJob()方法,它封裝了一些設定,如下圖所示:
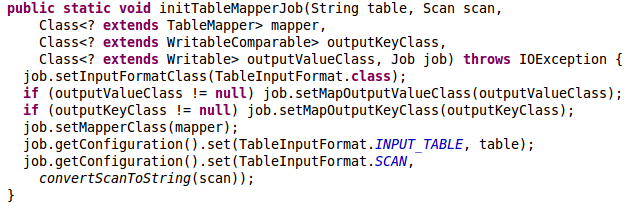
從圖中我們可以知道該方法會幫我們設定InputFormatClass為TableInputFormat,還有一些相關設定,例如:TableInputFormat.INPUT_TABLE用來設定輸入的Table,TableInputFormat.SCAN用來設定Scan(由於Scan是一個物件,所以必須透過convertScanToString()方法來轉碼成Base64編碼)
