在資訊檢索的領域中~ 「Lucene」算是表現最為突出的一個全文檢索函式庫,想當然~ 本站的搜尋功能就是用「Lucene」來建構的~
不過~ 雖然Lucene相當好用~ 但... 如果「index」太大呢?或者「index」比一整顆硬碟還大呢?是否需要負載平衡來分散處理?...
「Katta」就是要改善這樣的問題~ 所以它系建構在「Hadoop」和「Zookeeper」之上~ 採用「Apache Version 2 License」,並在今年的9月17日釋出了「katta-0.1.0」版~
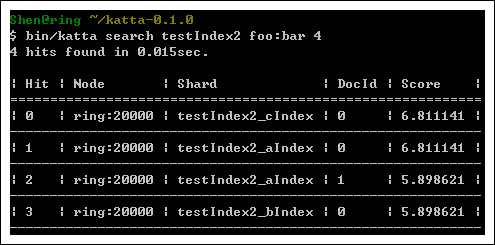
上圖就是我在Cygwin的環境下照著「katta : Getting started」所跑出來的測試結果~ 總之又是一個值得關注的Project~ 期待它能隨著Zookeeper的腳步加入Apache的計畫之下~
katta是什麼呢?
.環尾狐猴
相關資源
.find23.net: katta-overview(pdf)
.find23.net: katta, pig and hadoop in production - experience report slides

但是 Doug Cutting 有負責另一個類似的項目 Bailey
不知道差別在哪裡
台灣還蠻少人關注這個項目的,反倒是對岸的資訊比較多。
我這邊有做用 Hadoop M/R 來建立 index(100G)
另外有實作分散搜尋的 Lucene
Zookeeper 的部分還在想要怎麼整合進來
而另外 Hadoop 的唯一 NameNode 是企業應用上 HA 必須解決的問題,目前還在想辦法整合中。
有機會可以討論討論。
2008-10-21 14:27:37
Bailey Project到目前為止還沒有任何的釋出動作,我也不曉得它還有沒有持續在進行~
另外就我目前所知道的,NameNode仍然是SPOF,至於實際整合Zookeeper,我手邊目前沒有可以讓我玩的機器,所以我也還沒試過,有機會可以保持分享討論!謝謝。
2008-10-22 01:28:54